
I am currently pursuing a Ph.D. degree (JST DoGS SPRING Fellowship) at the Graduate School of Informatics, Kyoto University, Japan. I am a member of the LSTA Lab., where I conduct research on multimodal document understanding, optical character recognition, and historical document analysis. If you are interested in any form of academic collaboration, please feel free to email me.
I received my Master of Science (M.S.) degree in 2025 from the Graduate Institute of Networking and Multimedia, National Taiwan University, Taipei, Taiwan. I was a member of NTU imLab, and my master’s thesis focused on 3D Gaussian Splatting (3DGS) and 3D head reconstruction.
I obtained my Bachelor of Science (B.S.) degree in 2023 in Electrical and Computer Engineering from Tamkang University, New Taipei City, Taiwan, where I graduated first in my department (1/68). I conducted my undergraduate research at the Advanced Mixed-Operation System Laboratory (AMOS Lab.) at Tamkang University, focusing on object detection, document image binarization, and image super-resolution.
My primary research interests include Multimodal Learning (Vision-Language Models), Computer Vision (Optical Character Recognition, Object Detection, Document Understanding), Image Processing (Document Image Enhancement and Binarization, Image Super-Resolution), Natural Language Processing (Large Language Models), and Computer Graphics (3D Gaussian Reconstruction and Blendshapes).
I have published numerous papers in international journals and conferences 
I am highly active in international academic activities and currently serve as a reviewer for several international journals, including IEEE TVCG, PR, KBS, and NN, as well as for international conferences such as AAAI, ICASSP, and IJCNN 
📢 News
- 2026.05: One paper is accepted by International Journal on Document Analysis and Recognition, oral presentation at ICDAR, Vienna, Austria.
- 2026.04: One paper is accepted by IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing.
- 2026.01: Two papers are accepted by IEEE VR 2026 (Poster), Daegu, Korea.
- 2026.01: One paper is accepted by ICASSP 2026 (Poster), Barcelona, Spain.
- 2025.12: One paper is accepted by IET Image Processing.
- 2025.11: I receive the Kyoto University DoGS SPRING Fellowship for my Phd studies.
- 2025.08: One paper is accepted by APSIPA ASC 2025 (Oral), Singapore.
- 2025.08: One paper is accepted by ADMA 2025 (Short Paper), Kyoto, Japan.
- 2025.06: I receive an offer for a PhD student at Kyoto University, Kyoto, Japan.
- 2025.06: My master's thesis project is now available.
- 2025.03: One paper is accepted by IEEE Access.
- 2025.01: One paper is accepted by ICRA 2025 (Oral), Atlanta, USA.
- 2024.09: One paper is accepted by Knowledge-Based Systems.
- 2024.08: One paper is accepted by ICONIP 2024 (Oral), Auckland, New Zealand.
- 2024.05: One paper is accepted by Electronics Letters.
- 2023.11: One paper is accepted by Scientific Reports.
- 2023.08: One paper is accepted by PRICAI 2023 (Oral), Jakarta, Indonesia.
- 2023.07: I receive an offer for a Master student at National Taiwan University, Taipei, Taiwan.
- 2023.06: One paper is accepted by Multimedia Tools and Applications.
- 2022.11: One paper is accepted by Journal of Real-Time Image Processing.
- 2022.10: ECCV 2022 Competition - Google Universal Image Embedding Challenge Silver Medal.
- 2022.07: One paper is accepted by IEEE Access.
- 2021.07: My research project receives a grant from Tamkang University.
- 2020.12: I join Advanced Mixed-Operation System Laboratory (AMOS Lab.) of Tamkang University.
📄 Publication
🔥🔥🔥 Optical Character Recognition
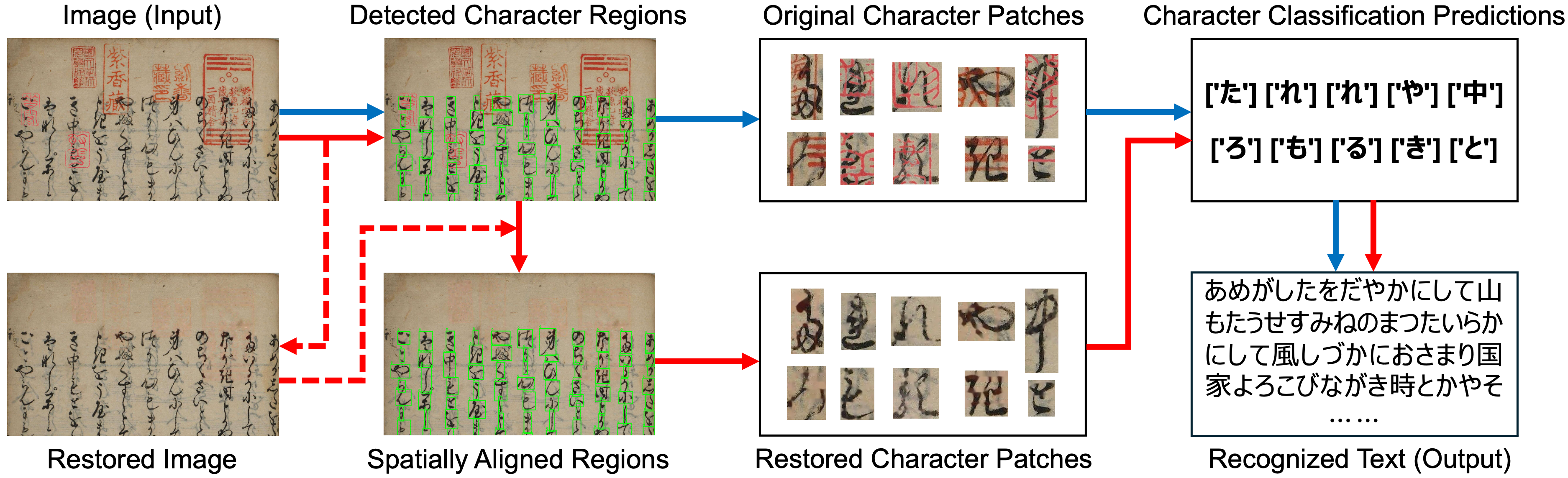
Seal-Robust KCR: A Robust Kuzushiji Character Recognition Framework under Seal Interference
Rui-Yang Ju, Kohei Yamashita, Hirotaka Kameko, Shinsuke Mori
🔥🔥🔥 Document Image Binarization
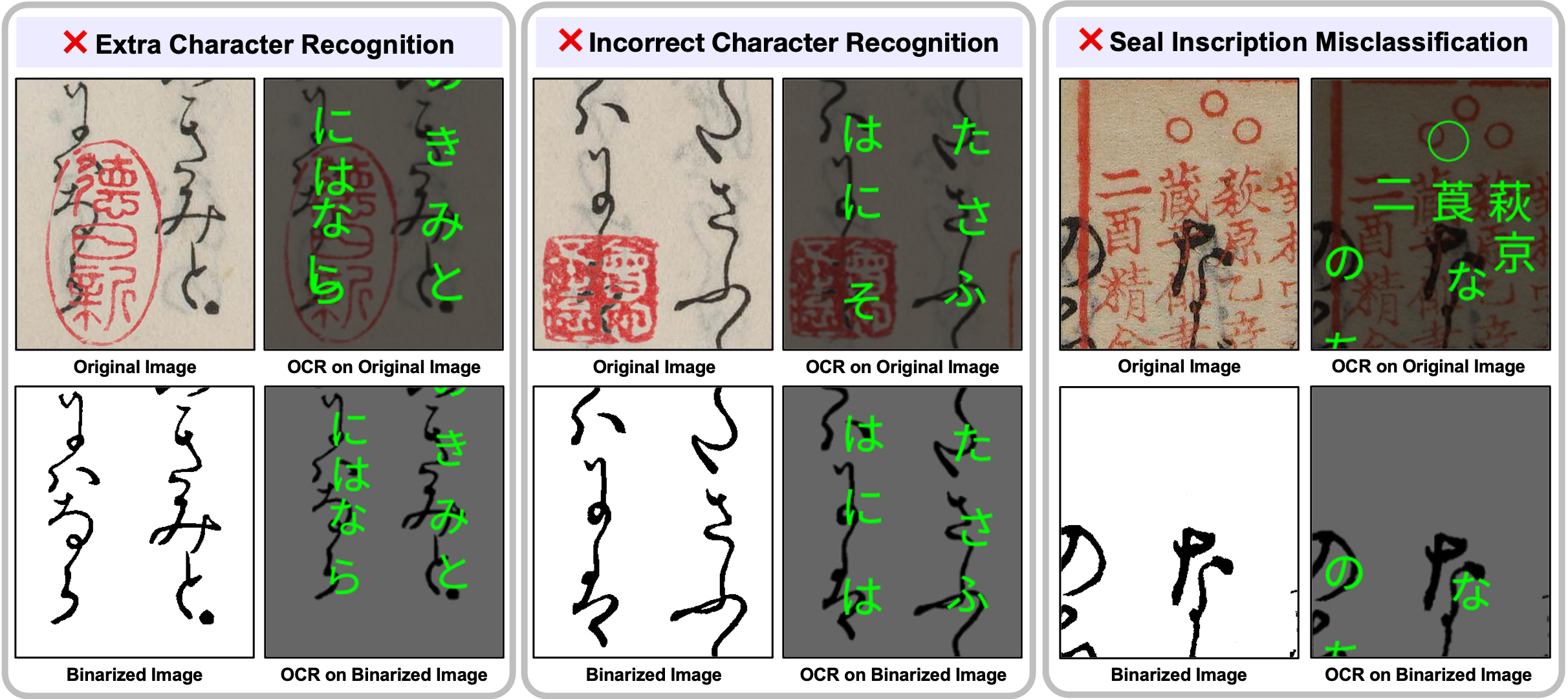
DKDS: A Benchmark Dataset of Degraded Kuzushiji Documents with Seals for Detection and Binarization
Rui-Yang Ju, Kohei Yamashita, Hirotaka Kameko, Shinsuke Mori

Three-stage Binarization of Color Document Images Based on Discrete Wavelet Transform and Generative Adversarial Networks
Rui-Yang Ju, Yu-Shian Lin, Yanlin Jin, Chih-Chia Chen, Chun-Tse Chien, Jen-Shiun Chiang
Under ReviewMFE-GAN: Efficient GAN-based Framework for Document Image Enhancement and Binarization with Multi-scale Feature Extraction, Rui-Yang Ju, KokSheik Wong, Yanlin Jin, Jen-Shiun Chiang.APSIPA ASC 2025Efficient Generative Adversarial Networks for Color Document Image Enhancement and Binarization Using Multi-scale Feature Extraction, Rui-Yang Ju, KokSheik Wong, Jen-Shiun Chiang.PRICAI 2023CCDWT-GAN: Generative Adversarial Networks Based on Color Channel Using Discrete Wavelet Transform for Document Image Binarization, Rui-Yang Ju, Yu-Shian Lin, Jen-Shiun Chiang, Chih-Chia Chen, Wei-Han Chen, Chun-Tse Chien.
🔥🔥 Multimodal Learning
An End-to-End Multimodal System for Subtitle Recognition and Chinese-Japanese Translation in Short Dramas
Jing An, Haofei Chang, Rui-Yang Ju, Jinhua Su, Yanbing Bai, Xin Qu
🔥🔥 3D Gaussian Reconstruction and Blendshapes

ToonifyGB: StyleGAN-based Gaussian Blendshapes for 3D Stylized Head Avatars
Rui-Yang Ju, Sheng-Yen Huang, Yi-Ping Hung
IEEE VR 2026 PosterGlassesGB: Controllable 2D GAN-Based Eyewear Personalization for 3D Gaussian Blendshapes Head Avatars, Rui-Yang Ju, Jen-Shiun Chiang.
🔥🔥 Fracture Detection
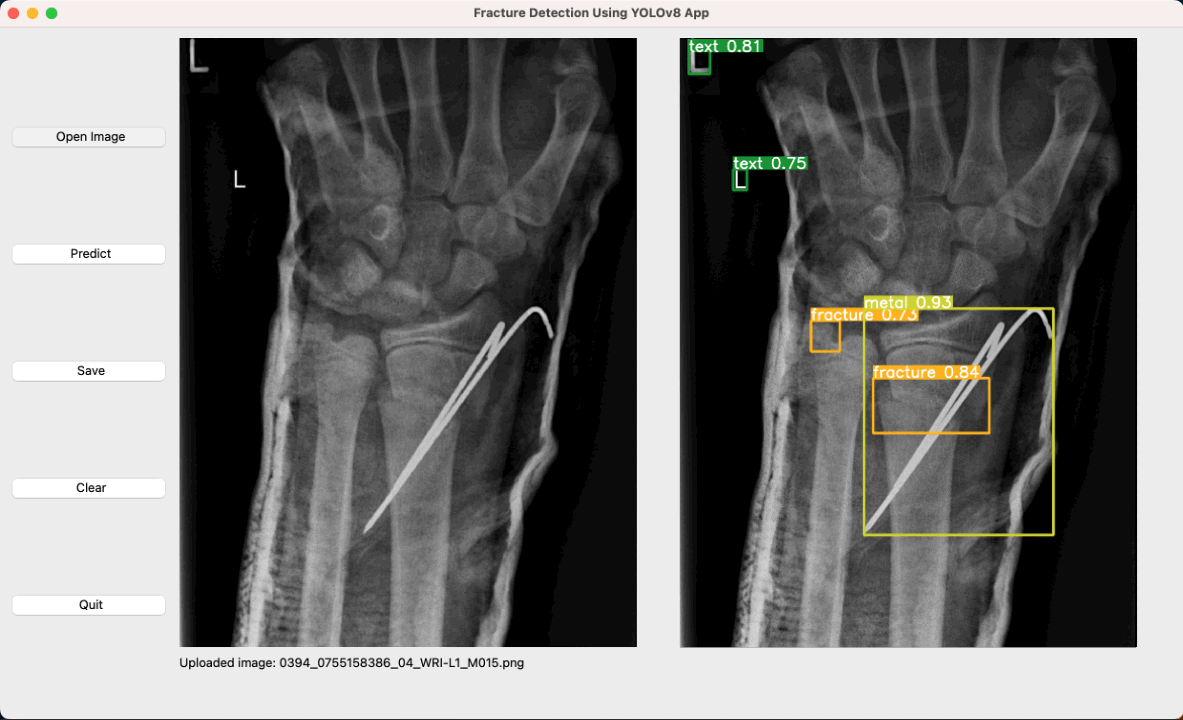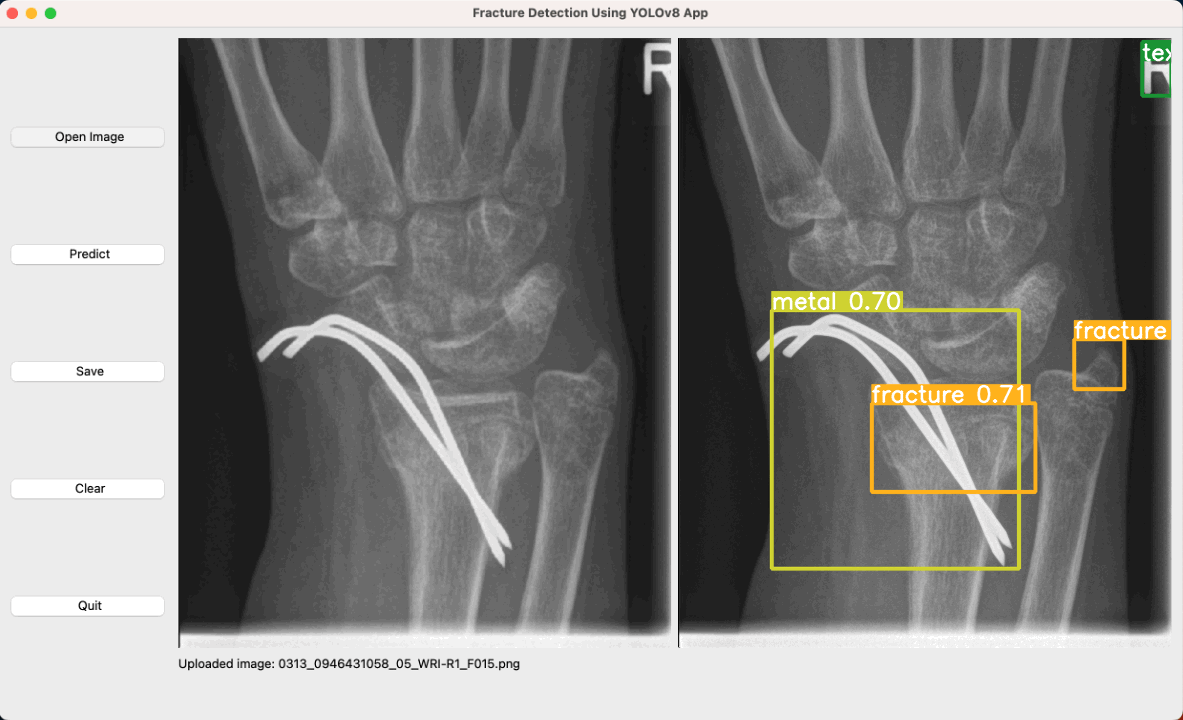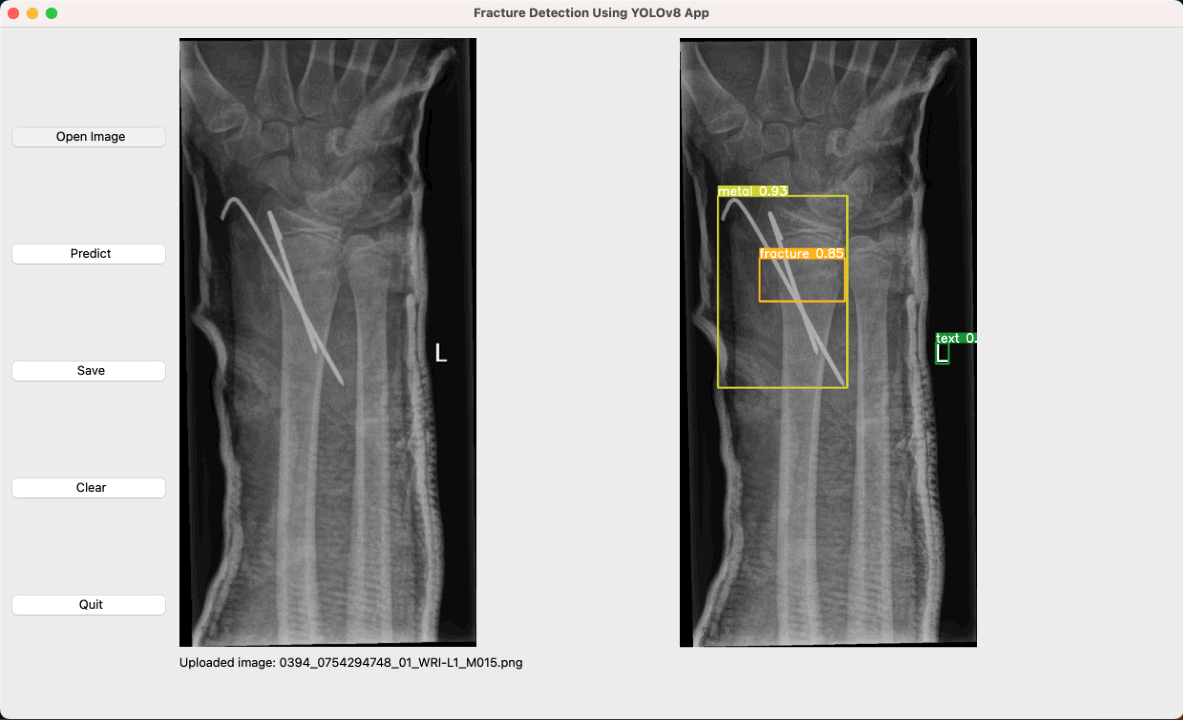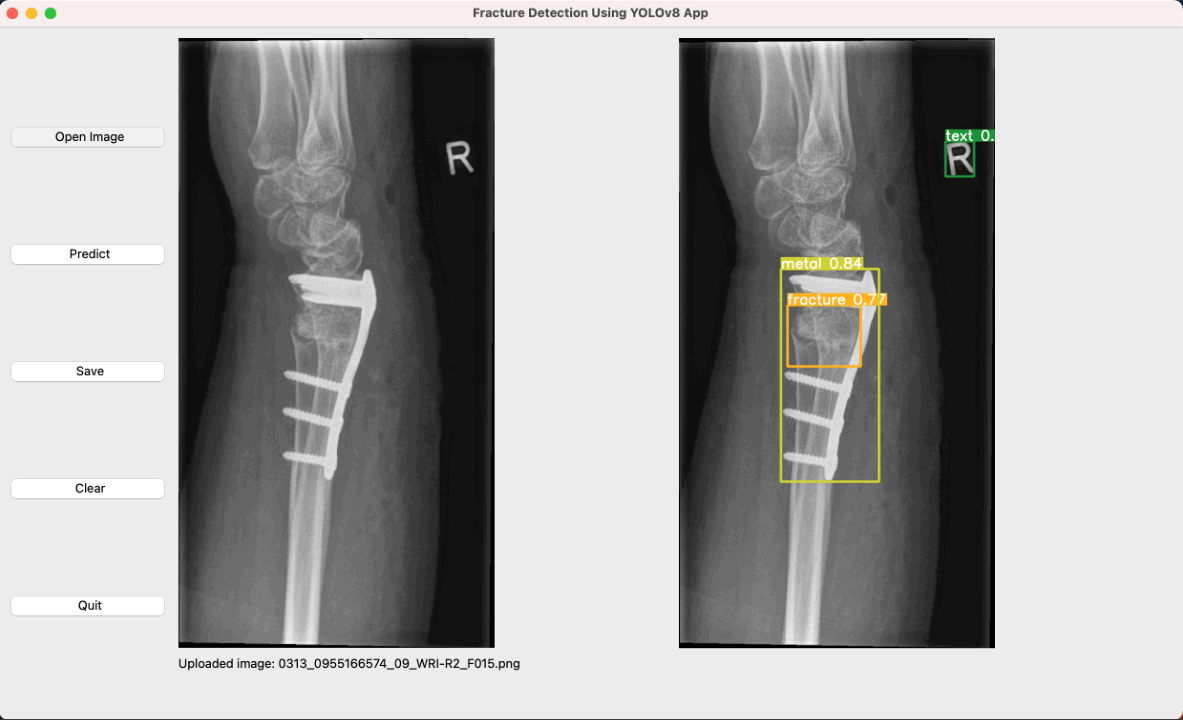
Fracture Detection in Pediatric Wrist Trauma X-ray Images Using YOLOv8 Algorithm
Rui-Yang Ju, Weiming Cai
IET Image Processing 2025Pediatric Wrist Fracture Detection Using Feature Context Excitation Modules in X-ray Images, Rui-Yang Ju, Chun-Tse Chien, Enkaer Xieerke, Jen-Shiun Chiang.IEEE Access 2025YOLOv8-AM: YOLOv8 Based on Effective Attention Mechanisms for Pediatric Wrist Fracture Detection, Chun-Tse Chien, Rui-Yang Ju, Kuang-Yi Chou, Enkaer Xieerke, Jen-Shiun Chiang.Electronics Letters 2024YOLOv9 for Fracture Detection in Pediatric Wrist Trauma X-ray Images, Chun-Tse Chien, Rui-Yang Ju, Kuang-Yi Chou, Jen-Shiun Chiang.ICONIP 2024YOLOv8-ResCBAM: YOLOv8 Based on An Effective Attention Module for Pediatric Wrist Fracture Detection, Rui-Yang Ju, Chun-Tse Chien, Jen-Shiun Chiang.
🔥🔥 Image Super-Resolution

Resolution enhancement processing on low quality images using swin transformer based on interval dense connection strategy
Rui-Yang Ju, Chih-Chia Chen, Jen-Shiun Chiang, Yu-Shian Lin, Wei-Han Chen, Chun-Tse Chien
🔥 Other
-
J-STARS 2026Two-Stage Framework for Efficient UAV-Based Wildfire Video Analysis with Adaptive Compression and Fire Source Detection, Yanbing Bai, Rui-Yang Ju, Lemeng Zhao, Junjie Hu, Jianchao Bi, Erick Mas, Shunichi Koshimura. -
ADMA 2025From Roads to Lights: Satellite Evidence on Smart City Planning, Yang Yang, Tianzhi Wu, Lize Zheng, Rui-Yang Ju, Yanbing Bai. -
ICRA 2025ORB-SfMLearner: ORB-Guided Self-supervised Visual Odometry with Selective Online Adaptation, Yanlin Jin, Rui-Yang Ju, Haojun Liu, Yuzhong Zhong. -
JRTIP 2023Efficient Convolutional Neural Networks on Raspberry Pi for Image Classification, Rui-Yang Ju, Ting-Yu Lin, Jia-Hao Jian, Jen-Shiun Chiang. -
IEEE Access 2022ThreshNet: An Efficient DenseNet Using Threshold Mechanism to Reduce Connections, Rui-Yang Ju, Ting-Yu Lin, Jia-Hao Jian, Jen-Shiun Chiang, Wei-Bin Yang.
🛠️ Professional Service
Journal Reviewer
View more
- IEEE Transactions on Visualization and Computer Graphics.
- Pattern Recognition.
- Knowledge-based Systems.
- Neurocomputing.
- Neural Networks.
- IEEE Signal Processing Letters.
- Engineering Applications of Artificial Intelligence.
- IET Signal Processing
- Alexandria Engineering Journal.
- Computer Vision and Image Understanding.
- Multimedia Tools and Applications.
- The Visual Computer.
- iScience.
- Scientific Reports.
- Engineering Reports
- npj Heritage Science.
- Cognitive Computation.
- International Journal of Multimedia Information Retrieval.
- International Journal of Machine Learning and Cybernetics.
- Plos One.
- Journal of Real-Time Image Processing.
- International Journal of Computational Intelligence Systems.
- The Journal of Supercomputing.
- Frontiers in Computer Science.
- Frontiers in Medicine.
- Signal, Image and Video Processing.
- Telecommunication Systems.
- Journal of Engineering.
- Franklin Open.
- Journal of King Saud University Computer and Information Sciences.
- Computer Methods in Biomechanics and Biomedical Engineering: Imaging & Visualization.
Conference Committee and Reviewer
View more
- AAAI Conference on Artificial Intelligence (AAAI), Montréal, Canada, 2027.
- International Joint Conference on Neural Networks (IJCNN), Cape Town, South Africa, 2027.
- Pacific Rim International Conference on Artificial Intelligence (PRICAI), Guangzhou, China, 2026.
- IEEE International Conference on Systems, Man, and Cybernetics (SMC), Bellevue, WA, USA, 2026.
- ACM Conference on Human Factors in Computing Systems (CHI), Barcelona, Spain, 2026.
- International Joint Conference on Neural Networks (IJCNN), Maastricht, Netherlands, 2026.
- IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 2026.
- AAAI Conference on Artificial Intelligence (AAAI), Singapore, 2026.
- Pacific Rim International Conference on Artificial Intelligence (PRICAI), Wellington, New Zealand, 2025.
- International Joint Conference on Neural Networks (IJCNN), Rome, Italy, 2025.
- IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Hyderabad, India, 2025.
- Pacific Rim International Conference on Artificial Intelligence (PRICAI), Kyoto, Japan, 2024.
- Pacific Rim International Conference on Artificial Intelligence (PRICAI), Jakarta, Indonesia, 2023.
🏅 Honor and Award
- Japan Science and Technology Agency (JST), DoGS SPRING Fellowship, Oct. 2025.
- National Taiwan University, Graduate Research Assistantship, Feb. 2024.
- National Taiwan University, Postgraduate Scholarship, Jan. 2024; Jul. 2024; Jan. 2025.
- Sino International Business Innovation Association (SIBIA), Gratitude and Heritage Scholarship, Mar. 2021; Mar. 2022; May 2024.
- Tamkang University, Undergraduate Research Fellowship, Aug. 2021.
- Tamkang University, Excellent Academic Performance Award (Top 1% Ranking), May 2021; Dec. 2022.
🎓 Education
- Graduate School of Informatics, Kyoto University, Kyoto, Japan, 2025.10 - 2028.09.
- Graduate Institute of Networking and Multimedia, National Taiwan University, Taipei, Taiwan, 2023.09 - 2025.06.
- Electrical and Computer Engineering, Tamkang University, New Taipei, Taiwan, 2019.09 - 2023.06.